5分钟学会制作论文中的Table 1
1、什么是Table 1?
Table 1即流行病学或临床研究发表的文章中第一张表格,功能是向读者展示研究人群的基本特征。
2、本文详细介绍用Stata绘制Table 1
Stata较SPSS可重复性强,且语句更为直观。当研究过程中有数据变动时(增删变量、更改变量名、修改数据),我们只需改动少量或甚至无需改动语句,重新“run”一遍,即可重现Table 1。
操作较SAS、R更为简便,上手快,且结果输出可满足出版要求。临床试验中常常涉及试验组和对照组比较,应用Stata绘制Table 1无需对各个变量单独计算p值;结果可自动导出至excel,只需随后复制到文章中即可,既节约了时间也可避免手动输入时出错。
3、怎样用Stata绘制Table 1?
今天,我们就以Stata自带数据库auto.dta为例,教你5分钟描述研究对象基本特征——绘制Table 1。
分析前准备
首先,初次使用table1 command之前,我们需要在Stata中安装table1这个package。将ssc install table1输入到command line中并运行,即可安装。
. ssc install table1
导入auto.dta数据库:
. sysuse auto.dta, clear
总体描述
总体描述,即研究问题不涉及分组比较,只想把所有研究对象看作一个整体分析,在Table 1中描述其基本特征。
例如,在auto数据集中,我们想描述整个数据库中国产、进口车辆各占多少百分比,维修次数分布,车体长度均值及标准差(假设为正态分布),价格的中位数及IQR(假设为偏态分布)。这时,可以使用table1命令实现:
. table1,vars(foreign bine \ rep78 cate \ length contn \ price conts)
屏幕显示:
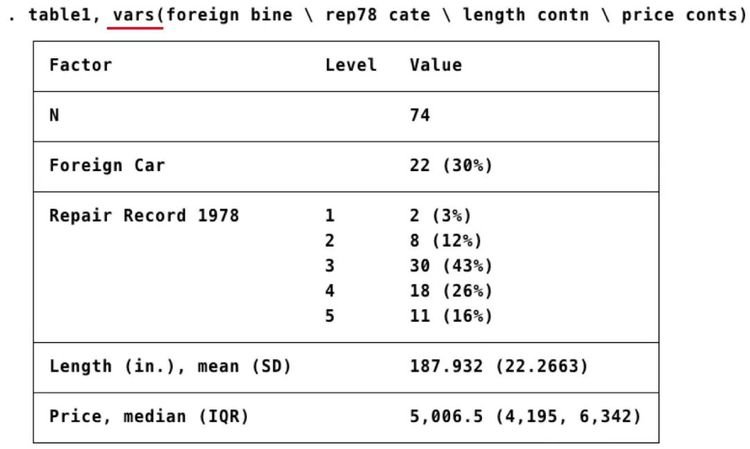
在vars的圆括号中输入需要在Table 1中描述的变量,并在空格后明确每个变量的类型:
-bin/bine:二分类变量;
-cat/cate:多分类变量;
-contn:连续型变量,正态分布,给出均数及标准差;
-conts:连续型变量,偏态分布,给出中位数及IQR;
各变量之间需使用“\”间隔开(*此处一定要注意斜线的方向*)。
本例中,foreign(车辆产地)为二分类变量,rep78(维修次数)为多分类变量,length(车体长度)为正态分布的连续型变量,price(价格)为偏态分布的连续型变量。故我们分别将foreign和rep78的数据类型设置为bine和cate(或可简写为bin和cat),length和price的类型设置为contn和conts。
*需要注意的是:对于二分类变量foreign和多分类变量rep78,在总体比较时,设置变量类型为bine和cate或者bin和cat是没有区别的;但分组比较时(见下一部分),选择的统计方法是不同的*
分组比较
实际研究中,我们的研究问题常涉及分组比较。例如,此例中研究问题为国产车和进口车性能有无差别,那么在Table 1中,我们将按产地分组描述研究对象的基本特征并比较组间特征差异。使用by()选项,在括号中填入分组变量即可。
如前所述,对变量设置不同类型(bine/bin、cate/cat、contn、conts),Stata在分组比较时,默认选取的检验方法是不同的,如图1。
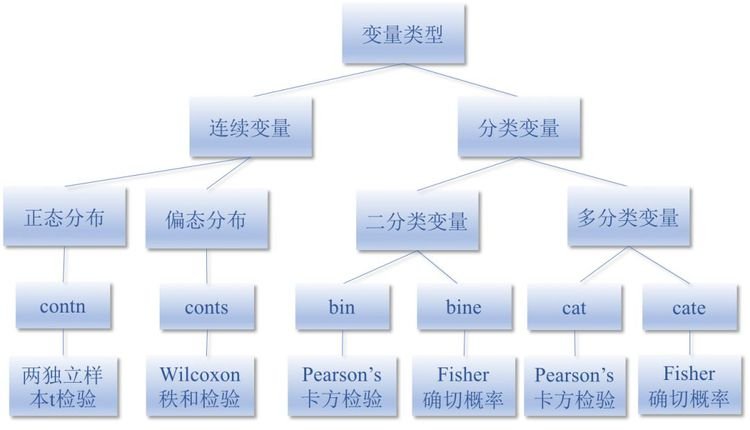
图1. Stata中的变量设置与假设检验方法
组间比较语句如下:
. table1,by(foreign) vars(rep78 cate \ length contn \ price conts)
屏幕显示:
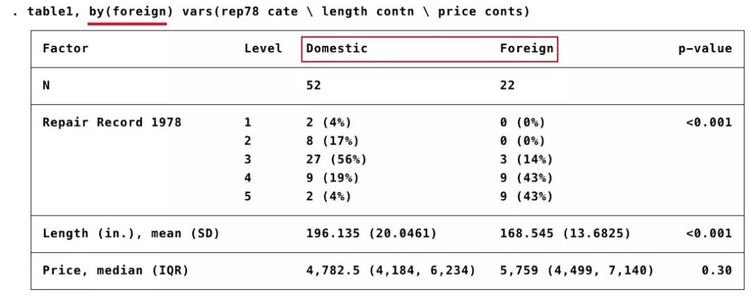
结果显示,国产车和进口车维修次数分布差异具有统计学意义(P< 0.001);国产车车体长度大于进口车,差异具有统计学意义(P< 0.001);两者价格差异无统计学意义(P = 0.30)。
Tabel 1的导出及存储
表格绘制完成后,可以通过saving()这个选项将绘制好的表格导出并存储至excel。以上述表格为例,仅在整个语句后面添加saving(),括号中输入自己需要存储的位置即可,操作如下:
. table1,by(foreign) vars(rep78 cate \ length contn \ price conts) saving(输入你指定的存储位置/表格名称.xls, replace)
*注意上述语句需出现在同一行,语句中存储位置和表格名称不要出现空格*
屏幕显示:
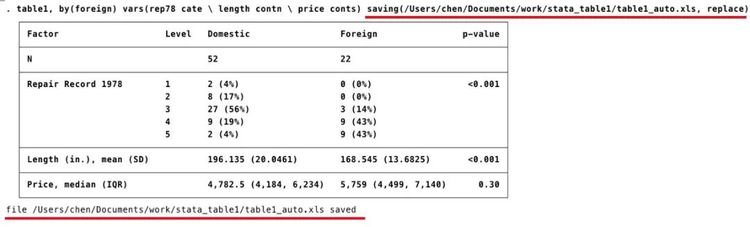
这样就在你指定的存储位置(Users/chen/Documents/work/stata_table1)生成了一个名为table1_auto的excel表格,如需将Table 1转至word文档中,直接从excel复制粘贴过去再按要求调整格式即可。这时,一个基本款Table 1已轻松生成。
Tabel 1的options及个性化设计
在实际应用过程中,我们还可利用table1命令中的众多options对表格显示内容进行个性化调整:
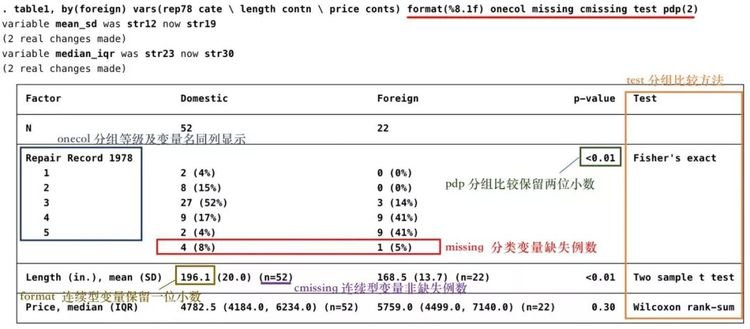
-format(%8.1f),cformat(%8.1f) 可分别设定对连续型变量及分类变量保留一位小数,括号中“%”是格式化代码,“8”是包含整数、小数及符号在内的总宽度,“.”代表小数点,“1”是小数点后位数,“f”是“fixed”的缩写,表示指定总宽度及保留小数位数(注意:小数点后位数一定要小于总宽度,此例中小数点后位数为“1” < 总宽度“8”,平时可以根据研究需要更改这两个数字);
-onecol可让多分类变量的分组等级显示在此变量名下方,而非单独成列;
-missing可将分类变量的缺失例数及比例显示出来,cmissing可报告连续型变量非缺失例数;
-test可将我们对每个变量所使用的特定分组比较方法显示在表格中;
-pdp(#)可设定分组比较p值保留小数位数,如pdp(2)为保留两位小数。
应用上述选项后语句为:
. table1, by(foreign) vars(rep78 cate \length contn \ price conts) format(%8.1f) onecol missing cmissing test pdp(2)
效果如下图:
现在,我们也学会了如何对Table 1进行个性化加工。
看了这期教程,是不是觉得用Stata描述研究对象基本特征方便易学呢?快打开Stata,自己试一试吧!